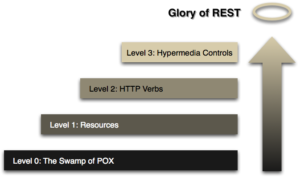
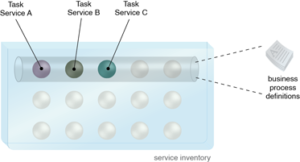
Como você faz o tratamento de erros de integração da sua empresa? Eu aposto que não deu a devida atenção para este assunto! Há quatro anos eu escrevi um post sobre Estratégia de Tratamento de Erros, porém, como os demais posts sobre SOA, parece que este assunto não fica desatualizado....
Saiba mais